El sistema operativo como controlador de recursos
El concepto del sistema operativo como algo que en primer lugar proporciona a sus usuarios una interfase conveniente entra en una visión de abajo hacia arriba. Un punto de vista alternativo, de arriba hacia abajo, sostiene que el sistema operativo está ahí para controlar todas las piezas de un complejo sistema. Las computadoras modernas constan de procesadores, memorias, cronómetros, discos, terminales, unidades de cinta magnética, interfases de red, impresoras laser y una amplia gama de otros dispositivos. Desde este punto de vista, la labor del sistema operativo es la proporcionar una asignación ordenada y controlada de los procesadores, memorias y dispostivos de E/S para los varios programas que compiten por ellos.Imagine lo que ocurriría si tres programas que están en ejecución en cierta computadora intentaran imprimir su salida en forma simultánea, en la misma impresora. Los primeros renglones de impresión serían del programa 1, los siguientes del programa 2, luego algunos del programa 3, etcétera. El resultado sería un caos. El sistema operativo puede poner orden en el caos potencial, al almacenar en el disco toda la salida destinada a la impresora. Al concluir uno de los programas, el sistema operativo podrá entonces copiar su salida desde el disco de archivo donde se encontraba hacia la impresora, mientras el otro programa continuaría generando más salida, sin importar el hecho de que la salida no sea dirigida a la impresora (todavía).
Si una computadora tiene varios usuarios, es todavía más evidente la necesidad del control y protección de la memoria, los dispositivos de E/S y demás recursos. Esta necesidad surge del hecho de que, con frecuencia, los usuarios deben compartir costosos recursos, como las unidades de cinta y máquinas de fotocomposición. Sin seńalar el aspecto económico, también se requiere a menudo compartir la información entre aquellos usuarios que trabajan juntos. En resumen, este punto de vista del sistema operativo sostiene que su principal tarea es la de llevar un registro de la utilización de los recursos, dar paso a las solicitudes de recursos, llevar la cuenta de su uso y mediar entre las solicitudes en conflicto de los distintos programas y usuarios.
La primera computadora digital real fue diseńada por el matemático inglés Charles Babbage (1792-1871). Aunque Babbage consumió gran parte de su vida y fortuna en el intento por construir su "máquina analítica", nunca logró que funcionara de manera adecuada, ya que esta era un diseńo puramente mecánico y la tecnología de su época no podía producir las ruedas, engranes, levas y demás partes mecánicas con la precisión que él necesitaba. Sobra decir que la máquina analítica no tenía un sistema operativo.
En estos primeras días, un solo grupo de personas diseńaba, construía, programaba, operaba y daba mantenimiento a cada máquina. Toda la programación se lleva a cabo en lenguaje de máquina absoluto y con frecuencia se utilizaban conexiones para controlar las funciones básicas de la máquina. Los lenguajes de programación eran desconocidos (incluso el lenguaje ensamblador). No se oía de los sistemas operativos. El modo usual de operación consistía en que el programador reservaba cierto periodo en una hoja de reservación pegada en la pared, iba al cuarto de la máquina, insertaba su conexión en la computadora y pasaba unas horas esperando que ninguno de los 20 000 o más bulbos se quemara durante la ejecución. La inmensa mayoría de los problemas eran cálculos numéricos directos, como por ejemplo el cálculo de valores para tablas de senos y cosenos.
A principios de la década de los cincuenta, la rutina mejoró un poco con la introducción de las tarjetas perforadas. Fue entonces posible escribir los programas en las tarjetas y leerlas en vez de insertar conexiones; por lo demás, el proceso era el mismo.
Estas máquinas se aislaban del exterior en cuartos de cómputo con aire acondicionado especial y un equipo de operadores profesionales para la ejecución. Sólo las grandes corporaciones, oficinas principales de gobierno o universidades podían cubrir los precios multimillonarios. Para ejecutar un trabajo (es decir, un programa o conjunto de programas), el programador debía primero escribir el programa en hojas de papel (en FORTRAN o ensamblador) para después perforar las tarjetas. Después debía llevar el paquete de tarjetas perforadas al cuarto de lectura y dárselas a uno de los programadores.
Al terminar la computadora el trabajo que estaba en ejecución, un operador pasaba a la impresora, separaba la salida y la pasaba al cuarto de salida, para que el programador la recogiera más tarde. Tomaría uno de los paquetes de tarjetas traídos del cuarto de entrada y lo leería. Si era necesario utilizar el compilador de FORTRAN, el operador debía tomarlo de un gabinete para archivos y leerlo. Se desperdiciaba demasiado tiempo de cómputo mientras los operadores caminaban en el cuarto de la máquina.
Dado el alto costo del equipo, no debe sorprender el hecho de que las personas buscaron en forma por demás rápida vías para reducir el tiempo invertido. La solución que, por lo general se adoptó, fue la de sistema de procesamiento por lotes. La idea subyacente era colectar una charola repleta de trabajos en el cuarto de entrada y leerlas después en una cinta magnética mediante una computadora pequeńa y relativamente barata, como la IBM 1401, que era muy buena en la lectura de cartas, copiado de cintas e impresión de la salida, pero no para los cálculos numéricos. Otras máquinas, más caras, como por ejemplo la IBM 7094, se utilizaban para el tiempo oficial. En la figura 2 se muestra esta situación.
Después de transcurrir una hora para colectar un lote de trabajos, la cinta se embobinaba y era llevada al cuarto de la máquina, donde se colocaba en una unidad de cinta. El operador cargaba entonces un programa especial (el antecesor del actual sistema operativo), el cual leía el primer trabajo de la cinta y lo ejecutaba. La salida se escribía en una segunda cinta, en vez de imprimirse. Al concluir cada trabajo, el sistema operativo leía en forma automática el siguiente trabajo y comenzaba a ejecutarlo. Al concluir con todo el lote, el operador retiraba las cintas de entrada y de salida, remplazaba la cinta de entrada con el siguiente lote y llevaba la cinta de salida a un 1401 para impresión fuera de línea (es decir, sin conectarse a la computadora principal).
La estructura de un trabajo de entrada normal se muestra en la figura 3. Comienza con una tarjeta $JOB, en la que se especifica el tiempo de ejecución en minutos, el número de cuenta al que se hace el cargo y el nombre del programador. Después viene una tarjeta $FORTRAN, la cual indica al sistema operativo que cargue el compilador de FORTRAN de la cinta de sistema. Seguía el programa a compilar y una tarjeta $LOAD, para indicar al sistema operativo que cargara el programa objeto recién compilado. (Los programas compilados se escribían con frecuencia en cintas de trabajo y debían cargarse en forma explícita). Después venía la tarjeta $RUN, que indicaba al sistema operativo que ejecutara el programa con los datos que le seguían. Por último, la tarjeta $END marcaba el final del trabajo. Estas primitivas tarjetas de control fueron los antecesores de los modernos lenguajes de control de las tareas y los intérpretes de comandos.
Las grandes computadoras de la segunda generación se utilizaron principalmente para los cálculos científicos y de ingeniería; por ejemplo, en la resolución de ecuaciones diferenciales parciales. Por lo general, se programaba en FORTRAN y lenguaje ensamblador. Los sistemas operativos más comunes eran FMS (Fortran Monitor System) e IBSYS, el sistema operativo de IBM para la 7094.
El desarrollo y mantenimento de dos líneas de productos completamente distintos era una propuesta cara para los fabricantes. Además, la mayoría de los nuevos clientes necesitaban una máquina pequeńa, pero con el tiempo deseaban una máquina más grande, que ejecutara sus programas anteriores pero de una manera más rápida.
IBM intentó resolver ambos problemas a la vez; para ello; introdujo el Sistema/360. El 360 era una serie de máquinas con software compatible, con un rango desde la 1401 hasta máquinas más poderosas que la 7094. Estas sólo diferían en el precio y el desempeńo (máximo de memoria, velocidad de procesador, número permitido de dispositivos de E/S, etcétera). Puesto que las máquinas tenían la misma arquitectura y conjunto de instrucciones, al menos en teoría, los programas escritos para una máquina podían ejecutarse en las otras. Además, la 360 se diseńó para hacer cálculos tanto científicos como comerciales. En los ańos siguientes, IBM produjo sucesores compatibles con la línea 360, con una tecnología más moderna, conocidas como las series 370, 4300, 3080 y 3090.
La 360 fue la primera línea principal de computadoras que utilizó los circuitos integrados (a pequeńa escala), lo que proporcionó una gran ventaja de precio y desempeńo con respecto de las máquinas de la segunda generación, construidas a partir de transistores individuales. Tuvo un éxito inmediato; la idea de las computadoras compatibles pronto fue adoptada por los demás fabricantes. Las descendientes de esas máquinas siguen utilizándose en los grandes centros de cómputo en la actualidad.
La enorme fuerza de la idea de "una familia" era al mismo tiempo su mayor debilidad. La intención era que todo el software, sistema operativo incluido, debía funcionar en todos los modelos. Debía poder ejecutarse en sistemas pequeńos, que con frecuencia remplazaban a la 1401 en el copiado de tarjetas a la cinta; también en sistemas muy grandes, que con frecuencia remplazaban a la 7094 en el pronóstico del tiempo y otros pesados cálculos. Debía ser bueno en los sistemas con pocos periféricos y en sistemas con muchos periféricos. Debía funcionar en los ambientes científicos y comerciales. Pero por encima de todo, debía ser eficaz en todos estos diversos usos.
No había forma de que IBM (o cualquiera otra empresa) pudiera escribir un pedazo de software que cumpliera con todos estos requisitos en conflicto. El resultado fue un sistema operativo enorme y extraordinariamente complejo, tal vez del doble o triple de magnitud que FMS. Constaba de millones de líneas en lenguaje ensamblador, escrito por miles de programadores, con miles y miles de errores, que requerían de un flujo continuo de nuevas versiones, en un intento por corregirlos. Cada nueva versión resolvía algunos errores pero introducía otros nuevos, por lo que es probable que el número de errores fuera constante con respecto del tiempo.
Uno de los diseńadores de OS/360, Fred Brooks, escribió un sarcástico e incisivo libro (Brooks, 1975), en el cual describe sus experiencias con OS/360. Aunque no podríamos resumir su libro aquí, basta decir que la portada muestra a una horda de bestias prehistóricas en un foso con brea. La portada del libro de Silberschatz et al. (1991) muestra una idea similar.
A pesar de su enorme tamańo y sus problemas, OS/360 y los sistemas operativos similares de la tercera generación producidos por otros fabricantes de computadoras realmente pudieron satisfacer, en forma razonable, a la mayoría de sus clientes. También popularizaron varias técnicas fundamentales, ausentes de los sistemas operativos de la segunda generación, de las cuales la más importante tal vez sea la de multiprogramación. En la 7094, si el trabajo en curso se detenía en espera de una cinta o de que concluyera otra labor de E/S, la UCP sólo se detenía a esperar hasta que la E/S finalizara. En los pesados cálculos científicos, con una cota para el uso de la UCP, la E/S no es frecuente, por lo que el tiempo perdido era insignificante. Pero en el procesamiento de los datos comerciales, el tiempo de espera para la E/S podría representar 80 o 90 por ciento del tiempo total, por lo que algo debía hacerse para evitar que la UCP estuviera inactiva por mucho tiempo.
La solución que se desarrolló fue la de partir la memoria en varias partes, con un trabajo distinto en cada partición, como se muestra en la figura 4. Mientras que un trabajo esperaba a que concluyera la E/S, otro podía estar usando la UCP. Si se podían mantener en la memoria principal los trabajos suficientes a la vez, la UCP estaría ocupada el 100 por ciento del tiempo. El mantenimiento de varios trabajos en memoria a la vez requería de un hardware especial, para proteger cada trabajo de las miradas curiosas y del conflicto con los demás, pero la 360 y otras máquinas de la tercera generación contaban con dicho hardware.
Otra de las características principales de los sistemas operativos de la tercera generación era la capacidad de leer trabajos de las tarjetas al disco, tan pronto como llegaran al cuarto de cómputo. Así, siempre que concluyera un trabajo, el sistema operativo podía cargar un nuevo trabajo del disco en la partición que quedaba desocupada y ejecutarlo. Esta técnica se llama spooling (de Simultaneous Peripheral Operation On Line, [operación simultánea y en línea de periféricos]) y también se utilizó para las salidas. Con el spooling, las 1401 ya no fueron necesarias y desapareció el transporte de las cintas de un lado al otro.
Aunque los sistemas operativos de la tercera generación eran adecuados para los grandes cálculos científicos y la ejecución de un procesamiento de grandes cantidades de datos comerciales, seguían siendo en esencia sistemas de procesamiento por lotes. Muchos de los programadores ligados a la época de la primera generación, cuando tenían toda la máquina para ellos solos por unas cuantas horas, de esta forma podían revisar y corregir sus programas de manera más rápida. Con los sistemas de la tercera generación, el tiempo transcurrido entre el envío de un trabajo y la obtención de la salida era a menudo de varias horas, por lo que una coma mal colocada podía provocar que la compilación fallara, con lo que el programador perdía la mitad del día.
Este deseo de una rápida respuesta preparó el camino para el tiempo compartido (timesharing), variante de la multiprogramación, en la que cada usuario tenía una terminal en línea. En un sistema con tiempo compartido, si 20 usuarios están conectados y 17 de ellos están pensando, platicando o tomando café, la UCP puede ser asignada a los tres trabajos que requieren servicio. Puesto que las personas que depuran los programas utilizan, por lo general, comandos cortos (por ejemplo, compilar un programa de cinco páginas) en vez de largos comandos (por ejemplo, ordenar una cinta con un millón de registros), la computadora podía dar un servicio rápido e interactivo a varios usuarios y, por otra parte, tal vez realizar trabajos con grandes lotes si la UCP está inactiva. Aunque el primer sistema serio de tiempo compartido (CTSS) fue desarrollado en MIT en una 7094 con modificaciones especiales (Corbato et al., 1962), este no se popularizó sino hasta que se difundió, durante la tercera generación, el hardware necesario para protección.
Después del éxito del sistema CTSS, MIT, Bell Labs y General Electric (que entonces eran los principales fabricantes de computadoras) decidieron emprender el desarrollo de una "utilería de computadora", una máquina que soportara a cientos de usuarios con tiempo compartido. Su modelo fue el sistema de distribución de la electricidad (si se necesita la corriente eléctrica, sólo hay que conectarse a un contacto en la pared y, dentro de los límites razonables, con ello se obtiene la corriente que se desee). Los diseńadores de este sistema, llamado MULTICS (MULTiplexed Information and Computing Service, Servicio de Información y Cómputo con Multiplexión), imaginaron una formidable máquina que proporcionaría corriente a cada persona en Boston. La idea de que, dentro de 20 ańos, máquinas tan poderosas como la GE-645 se vendieran como computadoras personales por unos cuantos miles de dólares, era ciencia ficción pura en aquella época.
Para no hacer muy grande la historia, MULTICS introdujo muchas ideas seminales en la bibliografía sobre computación, pero su construcción era mucho más ardua de lo esperado. Bell Labs abandonó el proyecto y General Electrics se retiró completamente del negocio de la computación. MULTICS llegó a ejecutarse de una manera que fuera útil en un ambiente de producción en MIT y algunos cuantos lugares más, pero el concepto de la utilería de computadora fue un fracaso. Aún hoy en día, MULTICS ha tenido una enorme influencia en los sistemas subsecuentes. Se describe en (Corbato et al., 1972; Corbato y Vyssotsky, 1965; Daley y Dennis, 1968; Organick, 1972; Saltzer, 1974).
Otro desarrollo fundamental durante la tercera generación fue el crecimiento fenomenal de las minicomputadoras, a partir de la DEC PDP-1 en 1961. La PDP-1 sólo tenía 4K de palabras de 18 bits, pero a ciento veinte mil dólares (menos del 5% del precio de una 7094), se vendió como pan caliente. Para cierto tipo de trabajo no numérico, era casi tan rápida como la 7094 y dió lugar a toda una nueva industria. Le siguió una serie de otras PDP (a diferencia de IBM, todas incompatibles), hasta llegar a la PDP-11.
Uno de los científicos de de Bell Labs que trabajó en el proyecto MULTICS, Ken Thompson, se encontró una pequeńa minicomputadora PDP-7 que nadie utilizaba e intentó escribir una versión desprotegida de MULTICS para un solo usuario. Este trabajo desembocó en el sistema operativo UNIX, que en la actualidad domina los mercados de las minicomputadoras y estaciones de trabajo, así como otros mercados.
La amplia disponibilidad del poder de cómputo, en particular, el poder de cómputo de gran interacción y que, por lo general, cuenta con gráficos excelentes, condujo al crecimiento de una gran industria de producción de software para las computadoras personales. Gran parte de este software es amigable con el(la) usuario(a), lo que indica que está destinado al usuario que no sabe nada acerca de las computadoras y que además no tiene la más mínima intención de aprender. Este fue un cambio fundamental con respecto a OS/360, cuyo lenguaje de control de tareas, JCL, era tan misterioso que se habían escrito libros enteros acerca de él (por ejemplo, Cadow, 1970).
Dos sistemas operativos han dominado la escena de las computadoras personales y las estaciones de trabajo: MS-DOS de Microsoft y UNIX. MS-DOS tiene un amplio uso en la IBM PC y otras máquinas con la UCP 8088 de Intel y sus sucesores, 80286, 80386 y 80486. Aunque la versión inicial de MS-DOS era relativamente primitiva, las subsecuentes versiones han incluido características más avanzadas, entre ellas algunas de UNIX. Este desarrollo no es del todo sorprendente, puesto que Microsoft es uno de los principales proveedores de UNIX.
El otro contendiente principal es UNIX, que domina en las computadoras que no utilizan a Intel, así como en las estaciones de trabajo, en particular en las que poseen chips de alto desempeńo RISC. Estas máquinas tienen en general la potencia de cómputo de una minicomputadora, aunque se dediquen a un sólo usuario, por lo que es lógico que estén equipadas con un sistema operativo diseńado en principio para las minicomputadoras, UNIX.
Un interesante desarrollo que comenzó a llevarse a cabo a mediados de la década de los ochenta ha sido el crecimiento de las redes de computadoras personales con sistemas operativos de red y sistemas operativos distribuidos. En un sistema operativo de red, los usuarios están conscientes de la existencia de varias computadoras y pueden conectarse con máquinas remotas y copiar archivos de una máquina a otra. Cada máquina ejecuta su propio sistema operativo local y tiene su propio usuario (o grupo de usuarios).
Por el contrario, un sistema operativo distribuido es aquel que aparece ante sus usuarios como un sistema tradicional de un solo procesador, aunque cuando esté compuesto por varios procesadores. En sistema distribuido verdadero, los usuarios no deben ser conscientes del lugar donde su programa se ejecute o del lugar donde se encuentran sus archivos; eso debe ser manejado en forma automática y eficaz por el sistema operativo.
Los sistemas operativos de red no tienen diferencias fundamentales con los sistemas operativos de un solo procesador. Es obvio que necsitan un controlador de interfase de la red y algo de software de bajo nivel para dirigirlo, al igual que programas que permitan la conexión y el acceso a un archivo remoto, pero estas características adicionales no modifican la estructura esencial del sistema operativo.
Los verdaderos sistemas operativos distribuidos requieren de algo más que ańadir un poco de código a un sistema operativo de un único procesador, puesto que los sistemas distribuidos y los centralizados difieren en aspectos críticos. Por ejemplo, los sistemas distribuidos permiten a menudo que un programa se ejecute mediante varios procesadores a la vez, por lo que necesitan algoritmos de asignación del tiempo más complejos, con el fin de optimizar la magnitud de paralelismo lograda.
Los retrasos de comunicación dentro de la red implican a menudo que estos (y otros) algoritmos deban ejecutarse con información incompleta, obsoleta e incluso incorrecta. Esta situación difiere en forma radical de un sistema de un solo procesador, en el cual el sistema operativo tiene toda la información acerca del estado del sistema.
HISTORIA DE LOS SISTEMAS OPERATIVOS
Los sistemas operativos han evolucionado a través de los ańos. En las secciones siguientes revisaremos este desarrollo. Puesto que los sistemas operativos han estado relacionados históricamente con la arquitectura de las computadoras en las cuales se ejecutan, analizaremos las generaciones sucesivas de computadoras para ver cómo eran sus sistemas operativos. Esta relación entre las generaciones de los sistemas operativos y las generacionres de computadoras es algo burda, pero proporciona cierta estructura en donde, de otra forma, no la habría.
La primera generación (1945-1955): Bulbos y conexiones
Después de los infructuosos esfuerzos de Babbage, hubo poco progreso en la construcción de computadoras digitales, hasta la Segunda Guerra Mundial. A mitad de la década de los cuarentas, Howard Aiken (Harvard), John von Neumann (Instituto de Estudios Avanzados, Princeton), J. Presper Eckert y William Mauchley (Universidad de Pennsylvania), así como Konrad Zuse (Alemania), entre otros, lograron construir máquinas de cálculo mediante bulbos. Estas máquinas eran enormes y llenaban cuartos completos con decenas de miles de bulbos, pero eran mucho más lentas que la computadora casera más económica en nuestros días.
La segunda generación (1955-1965): Transistores y sistemas de procesamiento por lotes
La introducción del transistor a mediados de los ańos cincuenta modificó en forma radical el panorama. Las computadoras se volvieron confiables, de forma que podían fabricarse y venderse a clientes, con la esperanza de que ellas continuaran funcionando lo suficiente como para realizar un trabajo en forma. Por primera vez, hubo una clara separación entre los diseńadores, constructores, operadores, programadores y personal de mantenimiento.
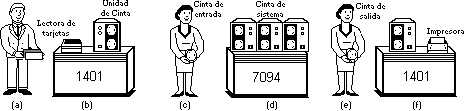
Figura 2. Uno de los primeros sistemas de procesamiento por lotes. (a) Los programadores llevan tarjetas a la 1401. (b) 1401 lee los lotes de tareas de la cinta. (c) El operador lleva la cinta de entrada a la 7094. (d) 7094 hace el cálculo. (e) El operador lleva la cinta de resultados a la 1401. (f) 1401 imprime los resultados.
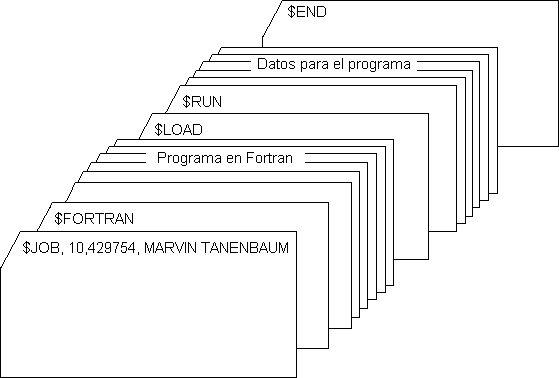
Figura 3. Estructura de una tarea común de FMS.
La tercera generación (1965-1980): Circuitos integrados y Multiprogramación
A principio de la década de los sesenta, la mayoría de los fabricantes de computadoras tenían dos líneas de productos, distintas y totalmente incompatibles. Por un lado, estaban las computadoras científicas de gran escala, orientadas a palabras, como la 7094, la cual se utilizaba en cálculos científicos y de ingeniería. Por el otro, estaban las computadoras comerciales, orientadas a carácteres, como la 1401, de uso común para el ordenamiento de cintas e impresión por los bancos y las compańías aseguradoras.
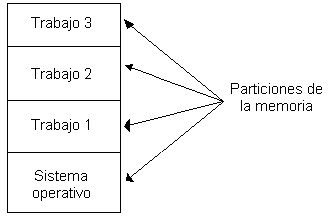
Figura 4. Un sistema de multiprogramación, con tres trabajos en memoria.
La cuarta generación (1980-1990): Computadoras personales
Con el desarrollo de los circuitos LCI (Large Scale Integration, Integración a Gran Escala), chips con miles de transistores en un centímetro cuadrado de silicio, se inició la era de la computadora personal. En términos de arquitectura, las computadoras personales no eran muy distintas de las minicomputadoras del tipo PDP-11, pero en términos del precio si eran distintas. Mientras que la minicomputadora permitió que un departamento de una empresa o universidad tuviera su propia computadora, el chip microprocesador hizo posible que una sola persona tuviera su propia computadora personal. Las computadoras personales más poderosas utilizadas por las empresas, universidades e instalaciones de gobierno reciben el nombre genérico de estaciones de trabajo, pero en realidad sólo son computadoras personales grandes. Por lo general, se conectan entre sí mediante una red.
BIBLIOGRAFÍA
Andrew S. Tanenbaum
Prentice Hall
Capítulo 1: Introducción
![]()